







Text-guided image editing aims to modify specific regions of an image according to natural language instructions while maintaining the general structure and the background fidelity. Existing methods utilize masks derived from cross-attention maps generated from diffusion models to identify the target regions for modification. However, since cross-attention mechanisms focus on semantic relevance, they struggle to maintain the image integrity. As a result, these methods often lack spatial consistency, leading to editing artifacts and distortions. In this work, we address these limitations and introduce LOCATEdit, which enhances cross-attention maps through a graph-based approach utilizing self-attention-derived patch relationships to maintain smooth, coherent attention across image regions, ensuring that alterations are limited to the designated items while retaining the surrounding structure. LOCATEdit consistently and substantially outperforms existing baselines on PIE-Bench, demonstrating its state-of-the-art performance and effectiveness on various editing tasks.
LOCATEdit introduces a novel approach to text-guided image editing by optimizing cross-attention maps using a Graph Laplacian-based framework. Our method first extracts cross-attention and self-attention maps, then constructs the Cross and Self-Attention (CASA) graph, capturing relationships between image patches based on self-attention weights. The CASA graph encodes spatial relationships, enforcing smoothness and coherence across semantically related regions. During editing, the optimized cross-attention maps, guided by the CASA graph structure, ensure localized modifications aligned precisely with text instructions, preserving image fidelity and preventing unwanted distortions. The complete pipeline involves computing attention maps, forming the CASA graph from self-attention relationships, and applying graph Laplacian optimization to enhance the editing quality.
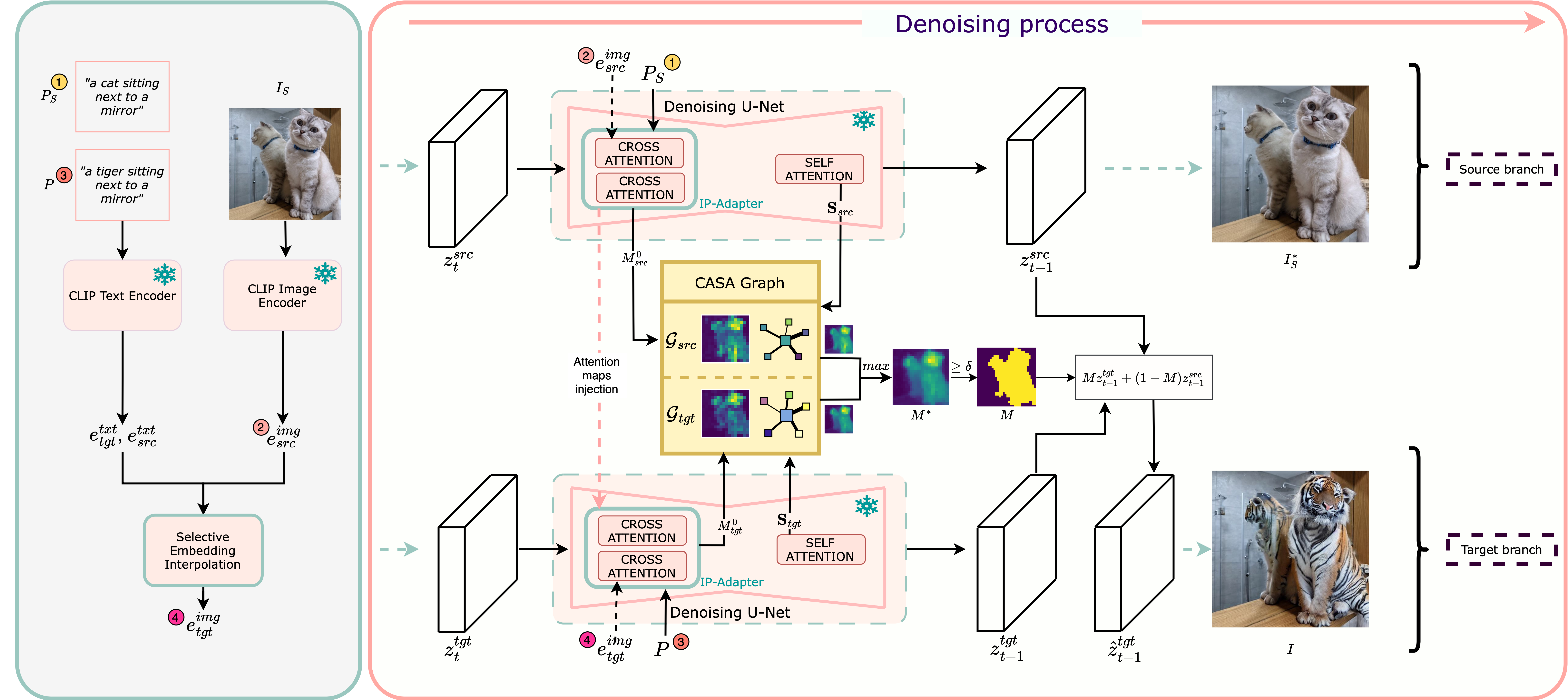
Framework Overview
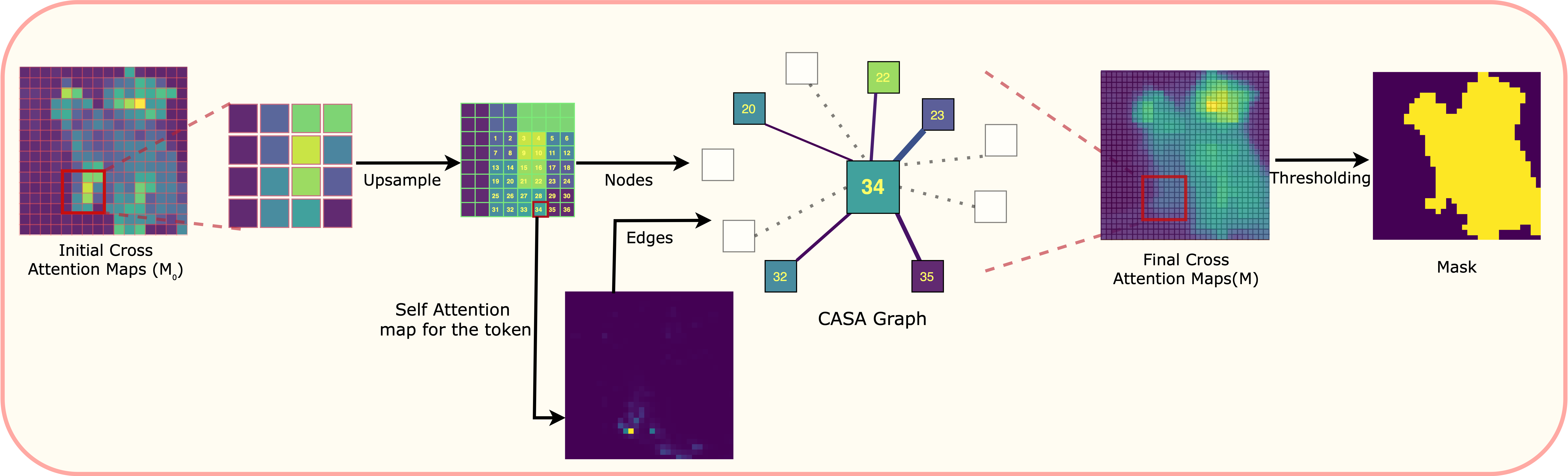
CASA graph